

What is Code coverage?
Code coverage is a measure which describes the degree of which the source code of the program has been tested. It is one form of white box testing which finds the areas of the program not exercised by a set of test cases. It also creates some test cases to increase coverage and determining a quantitative measure of code coverage.
In most cases, code coverage system gathers information about the running program. It also combines that with source code information to generate a report about the test suite's code coverage.
Why use Code Coverage?
Here, are some prime reasons for using code coverage:
- It helps you to measure the efficiency of test implementation
- It offers a quantitative measurement.
- It defines the degree to which the source code has been tested.
Code Coverage Methods
Following are major code coverage methods
- Statement Coverage
- Condition Coverage
- Branch Coverage
- Toggle Coverage
- FSM Coverage
Statement Coverage
What is Statement Coverage?
Statement coverage is a white box test design technique which involves execution of all the executable statements in the source code at least once. It is used to calculate and measure the number of statements in the source code which can be executed given the requirements.
Statement coverage is used to derive scenario based upon the structure of the code under test.

In White Box Testing, the tester is concentrating on how the software works. In other words, the tester will be concentrating on the internal working of source code concerning control flow graphs or flow charts.
Generally in any software, if we look at the source code, there will be a wide variety of elements like operators, functions, looping, exceptional handlers, etc. Based on the input to the program, some of the code statements may not be executed. The goal of Statement coverage is to cover all the possible path's, line, and statement in the code.
Let's understand this with an example, how to calculate statement coverage.
Scenario to calculate Statement Coverage for given source code. Here we are taking two different scenarios to check the percentage of statement coverage for each scenario.
Source Code:
Scenario 1:
If A = 3, B = 9

The statements marked in yellow color are those which are executed as per the scenario
Number of executed statements = 5, Total number of statements = 7
Statement Coverage: 5/7 = 71%

Likewise we will see scenario 2,
Scenario 2:
If A = -3, B = -9

The statements marked in yellow color are those which are executed as per the scenario.
Number of executed statements = 6
Total number of statements = 7

Statement Coverage: 6/7 = 85%

But overall if you see, all the statements are being covered by 2nd scenario's considered. So we can conclude that overall statement coverage is 100%.

What is covered by Statement Coverage?
- Unused Statements
- Dead Code
- Unused Branches
Decision Coverage
Decision coverage reports the true or false outcomes of each Boolean expression. In this coverage, expressions can sometimes get complicated. Therefore, it is very hard to achieve 100% coverage.
That's why there are many different methods of reporting this metric. All these methods focus on covering the most important combinations. It is very much similar to decision coverage, but it offers better sensitivity to control flow.

Example of decision coverage
Consider the following code-
Scenario 1:
Value of a is 2

The code highlighted in yellow will be executed. Here the "No" outcome of the decision If (a>5) is checked.
Decision Coverage = 50%
Scenario 2:
Value of a is 6

The code highlighted in yellow will be executed. Here the "Yes" outcome of the decision If (a>5) is checked.
Decision Coverage = 50%
| Test Case | Value of A | Output | Decision Coverage |
| 1 | 2 | 2 | 50% |
| 2 | 6 | 18 | 50% |
Branch Coverage
In the branch coverage, every outcome from a code module is tested. For example, if the outcomes are binary, you need to test both True and False outcomes.
It helps you to ensure that every possible branch from each decision condition is executed at least a single time.
By using Branch coverage method, you can also measure the fraction of independent code segments. It also helps you to find out which is sections of code don't have any branches.
The formula to calculate Branch Coverage:

Example of Branch Coverage
To learn branch coverage, let's consider the same example used earlier
Consider the following code
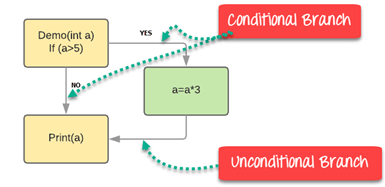
Branch Coverage will consider unconditional branch as well
| Test Case | Value of A | Output | Decision Coverage | Branch Coverage |
| 1 | 2 | 2 | 50% | 33% |
| 2 | 6 | 18 | 50% | 67% |
Advantages of Branch coverage:
Branch coverage Testing offers the following advantages:
- Allows you to validate-all the branches in the code
- Helps you to ensure that no branched lead to any abnormality of the program's operation
- Branch coverage method removes issues which happen because of statement coverage testing
- Allows you to find those areas which are not tested by other testing methods
- It allows you to find a quantitative measure of code coverage
- Branch coverage ignores branches inside the Boolean expressions
Condition Coverage
Conditional coverage or expression coverage will reveal how the variables or subexpressions in the conditional statement are evaluated. In this coverage expressions with logical operands are only considered.
For example, if an expression has Boolean operations like AND, OR, XOR, which indicated total possibilities.
Conditional coverage offers better sensitivity to the control flow than decision coverage. Condition coverage does not give a guarantee about full decision coverage
The formula to calculate Condition Coverage:

Example:

For the above expression, we have 4 possible combinations
- TT
- FF
- TF
- FT
Consider the following input
X=3
Y=4
|
(x
|
TRUE
|
Condition Coverage is ¼ = 25%
|
A=3
B=4
|
(a>b)
|
FALSE
|
Finite State Machine Coverage
Finite state machine coverage is certainly the most complex type of code coverage method. This is because it works on the behavior of the design. In this coverage method, you need to look for how many time-specific states are visited, transited. It also checks how many sequences are included in a finite state machine.
Which Type of Code Coverage to Choose
This is certainly the most difficult answer to give. In order to select a coverage method, the tester needs to check that the
- code under test has single or multiple undiscovered defects
- cost of the potential penalty
- cost of lost reputation
- cost of lost sale, etc.
The higher the probability that defects will cause costly production failures, the more severe the level of coverage you need to choose.
Code Coverage vs. Functional Coverage
| Code Coverage | Functional Coverage |
| Code coverage tells you how well the source code has been exercised by your test bench. | Functional coverage measures how well the functionality of the design has been covered by your test bench. |
| Never use a design specification | Use design specification |
| Done by developers | Done by Testers |
Code Coverage Tools
Here, is a list of Important code coverage Tools:
| Tool Name | Description |
| Coco | It is an Cross-platform and cross-compiler code coverage analysis for C, C++, SystemC, C#, Tcl and QML code. Automated measurement of test coverage of statements, branches and conditions. No changes to the application are necessary Learn more about coco |
| Parasoft Jtest | It accelerates Java software development by providing a set of tools to maximize quality and minimize business risks. Results from static analysis, JUnit tests, and code coverage are efficiently integrated with functional and manual testing results. Learn more about Parasoft Jtest |
| Cobertura | It is an open source code coverage tool. It measures test coverage by instrumenting a code base and analyze which lines of code are executing and which are not executed when the test suite runs. |
| Clover | Clover also reduces testng time by only running the tests which cover the application code which was modified since the previous build. |
| DevPartner | DevPartner enables developers to analyze Java code for Code Quality and Complexity. |
| Emma | EMMA supports class, method, line, and base block coverage, aggregated source file, class, and method levels. |
| JTest | JT's tool helps you to check functionalities like unit test-case generation, static analysis, regression testing, and code review. |
| Kalistick | Kalistick is a third party application which analyzes the codes with different perspectives. |
| CoView and CoAnt | Coding Software is a code coverage tool for metrics, mock object creation, code testability, path & branch coverage, etc. |
| Bullseye for C++ | BulseyeCoverage is a code coverage tool for C++and C. |
| Sonar | Sonar is an open code coverage tool which helps you to manage code quality. |
Advantages of Using Code Coverage
- Helpful to evaluate a quantitative measure of code coverage
- It allows you to create extra test cases to increase coverage
- It allows you to find the areas of a program which is not exercised by a set of test cases
Disadvantages of Using Code Coverage
- Even when any specific feature is not implemented in design, code coverage still report 100% coverage.
- It is not possible to determine whether we tested all possible values of a feature with the help of code coverage
- Code coverage is also not telling how much and how well you have covered your logic
- In the case when the specified function hasn't implemented, or a not included from the specification, then structure-based techniques cannot find that issue.
Summary
- Code coverage is a measure which describes the degree of which the source code of the program has been tested
- It helps you to measure the efficiency of test implementation
- Five Code Coverage methods are 1.) Statement Coverage 2.) Condition Coverage 3) Branch Coverage 4) Toggle Coverage 5) FSM Coverage
- Statement coverage involves execution of all the executable statements in the source code at least once
- Decision coverage reports the true or false outcomes of each Boolean expression
- In the branch coverage, every outcome from a code module is tested
- Conditional will reveal how the variables or subexpressions in the conditional statement are evaluated
- Finite state machine coverage is certainly the most complex type of code coverage method
- In order to select a coverage method, the tester needs to check the cost of the potential penalty, lost reputation, lost sale, etc.
- Code coverage tells you how well the source code has been exercised by your test bench while Functional coverage measures how well the functionality of the design has been covered
- Cobertura, JTest, Clover, Emma, Kalistick are few important code coverage tools
- Code Coverage allows you to create extra test cases to increase coverage
- Code Coverage does not help you to determine whether we tested all possible values of a feature

