

As engineering managers and developers, we often look for ways to speed up our workflows without sacrificing quality. Cursor, a code editor enhanced with AI capabilities, is one of those tools that, when used effectively, can be a true productivity multiplier. Over the last few weeks, I’ve been experimenting with it in real-world scenarios ;
building features, iterating on logic, and exploring new ideas.
Here’s a distilled set of practices that worked well.
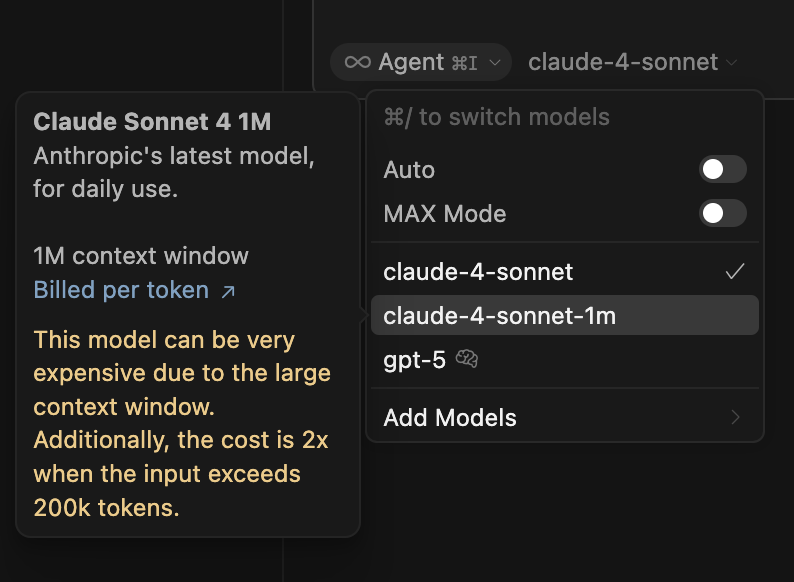
1. Use Sonnet for Code-Heavy Tasks
Cursor offers different models, but I’ve found Sonnet particularly effective for code. It’s faster, more reliable, and better at understanding context when the task is purely programming-related. Of course, it comes with some extra $$
2. Start a New Chat for New Features
When building something new, don’t clutter existing threads. A fresh chat keeps the scope clean, avoids accidental overwrites, and helps Cursor focus on the new feature instead of dragging in irrelevant context.
3. Provide Feedback — What Works, What Doesn’t
Cursor learns best when you guide it. If it suggests code that breaks existing logic or doesn’t align with your architecture, tell it. This prevents cascading mistakes and ensures the assistant builds on top of the right foundations.
4. Reuse Context From Old Chats
When extending or refining an existing feature, bring in snippets or references from past chats. This helps Cursor understand continuity and prevents it from reinventing already-working code.
5. Use Ask Mode for Code Questions
Cursor provides two main modes: Agent and Ask. For generating code, Agent works fine. But when only asking precise code-related questions, switch to Ask Mode — it’s sharper and less verbose.
Pro tip: Ask mode uses relatively less tokens, so save those $$ for sonnet mode.6. Always Tag Files for Clarity
When referencing code, tag files explicitly.
- Example:
@main.tsfor the core logic - Example:
Panel.tsxfor feature listings
This helps Cursor focus on the right file and avoid mixing unrelated logic.
7. Review Code Midway & Iterate With File Names
Don’t wait until the end to review. Midway through, ask Cursor to refine specific files — mentioning them by name. Iteration with file-level precision reduces cleanup time and avoids surprises later.
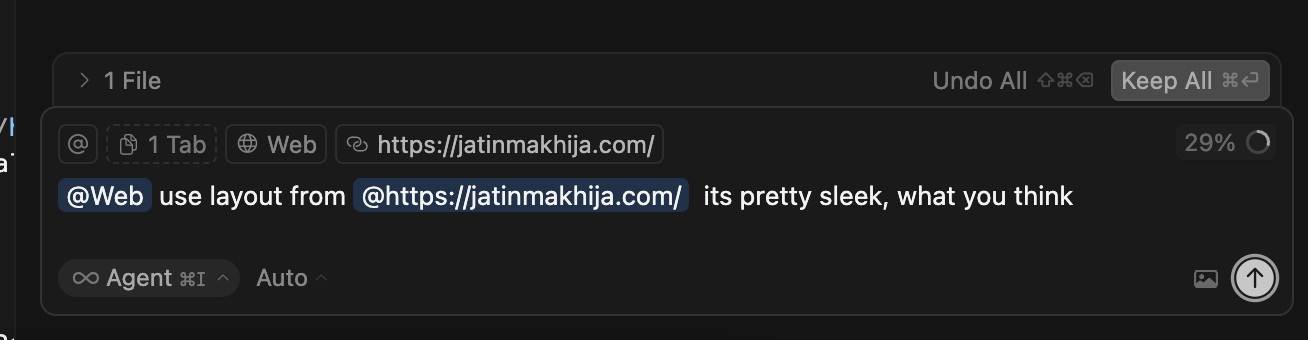
8. Use @Web for Research
Instead of manually Googling, use Cursor’s @Web feature to pull in fresh information. It’s especially useful for comparing libraries, exploring API usage, or checking security considerations.
9. Explore Official Docs With @Docs
When working with frameworks or libraries, @Docs is invaluable. Instead of scanning endless documentation pages, let Cursor fetch and summarize directly from official sources.

10. Use Images for Layout Context
Cursor isn’t limited to text. You can drop screenshots or sketches of UI layouts, and it will translate them into code structure. This works great for dashboards, component alignments, or mobile screens.
11. Add .cursorrules in the Root Directory
One hidden gem: Cursor always listens to the .cursorrules file if it exists at the project root. Define conventions, dos and don’ts, and style preferences here. This ensures consistency without repeating instructions every time.
Final Thoughts
Cursor is not a magic wand — it’s a tool that shines when used with structure and intention. By setting clear boundaries, reviewing iteratively, and leveraging features like @Web, @Docs, and .cursorrules, you can make Cursor a powerful coding partner for your team.
Used well, it won’t just save time; it will also elevate the quality of your codebase.
Last but not least, as the russian proverb goes, be it human or the code.




