So, you’ve created an exhaustive regression test suite for your APIs that runs as part of your continuous build and deploy process. You’ve run and even automated (cool!) load-tests that simulate magnitudes more users than your API will probably ever (but maybe) have. You’ve set up monitors that will catch any bug that sneaks past all these lines of defense. Hey - you’ve even automated the validation of the metadata that gets generated for your API every time you commit some changes to your code (high five)! Your API is ready for Primetime! (…or not.)
You probably know where this is going – but it’s somebody else’s problem, right? Isn’t there a CSO (Chief Security Officer) at your company that has this covered, with a long list of API security tools? Aren’t you using the latest updates to your frameworks? How could there be any security flaws in them? They are surely written by super-smart developers that avoid SQL Injection attacks, just as they would avoid crossing the street on a green light. And your API management vendor uses the latest OAuth implementation with tokens and nonces flying through the ether like bats in the night. All this talk about API Security is just a scare by vendors that want to sell you more tools. Right?
But deep down you know that API Security is something you need to take seriously – just like Facebook, SnapChat, Twitter, Bitly, Sony, Microsoft, Tinder, Apply, NBC, Evernote and many others decidedly did not. Nobody is going to bail you out if your customers’ credit card numbers are stolen, or your customers’ users’ personal dating data is published on a torrent website. And deep down you’re right.
So what to do? Just like you do when validating functionality and performance, try to break things – put your hacker cloak on and make the developers of your API (you?) shiver as you approach for the attack. And since even hackers need a little structure to their dwellings – let’s attempt to break this down somewhat – you wouldn’t want to fail at hacking your API, would you?
1) Know Thy Target
If you’re going to attack an API, then you must understand its perimeters… because the gate is where you often sneak in the Trojan horse.
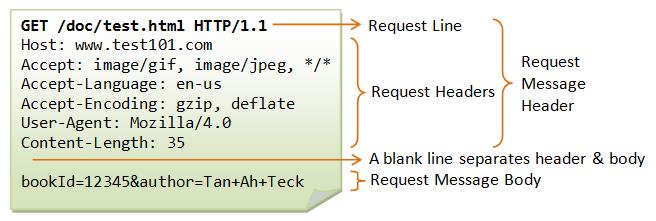
- HTTP: Most APIs today are using the HTTP protocol, which goes for both REST and SOAP. HTTP is a text-based protocol which therefore is fortunately very easy to read. Take, for example, the following HTTP Request:
 and the corresponding response:
and the corresponding response:
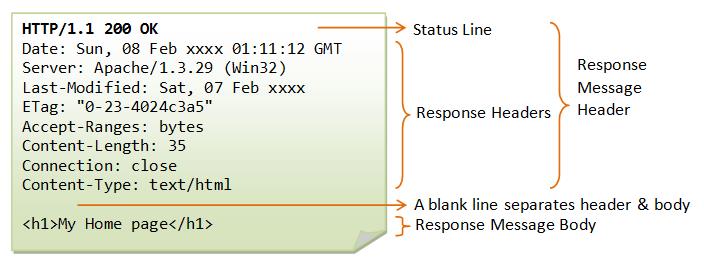
As you can see – the Request and Status lines, Request and Response Headers, and Request/Response messages are all plain text – easily readable, and easily customizable for performing a security attack.
- Message Formats: Messages sent over the web are sent using some message format. JSON is predominant in the REST world, while XML is mandatory in the SOAP world. Understand these formats (they’re easy too!) and how their peculiarities can be used to form an attack (we’ll get back to that later). And of course most formats can open for vulnerabilities if used incorrectly – PDF, Image formats like JPG and PNG, etc.
2) There is api security, and there is API Security
Security is a vague term; claiming an API is secure because it uses SSL or OAuth is false – there is more to an API than its transport-layer (although admittedly SSL goes a far way);
- Different Authorization/Authentication standards are at play for REST and SOAP; OAuth 1.X and 2.X, SAML, WS-Security, OpenID Connect, etc.
- SSL is great for transport-level security – but what if ones message data needs to be encrypted (so no one can read it) or signed (so you can be sure it hasn’t been tampered with) after it has been sent over HTTP? Perhaps you should be encrypting credit card numbers or sensitive customer data in your NoSQL database so that it’s useless if it should come into the wrong hands? SOAP APIs have the possibility to shine in this regard; WS-Security is a mature and complex standard handling most of these requirements. REST APIs are referred to as “startup initiatives” like JWT (JSON Web Tokens) or homegrown solutions.
As a hacker, you will be looking for these standards to be used improperly – or not at all where they should be. Perhaps getting access to someone’s credit card numbers is as simple as reusing a session token to get an authenticated user’s account information that isn’t encrypted in the message itself (more on incorrect session logic in a later post).
3) API Attack Surface Detection
Now that you’ve mastered the basics of web APIs and you’ve decided on an API to attack (your own API - don’t lose focus), you need to know where launch the attack; what is the “Attack Surface” of your API?
This can be tricky. Finding an Attack Surface for a UI-based solution (for example a web or mobile app) is straightforward: you can actually see the different input fields, buttons, file-uploads, etc. all waiting to be targeted during an attack. For an API, things are different - there is no UI to look at, just an API endpoint. But to launch a “successful” attack on an API, we need to know as much as possible about the API’s endpoints, messages, parameters and behavior. The more we know, the merrier our attack will be.
Fortunately, there are a number of “helpful” API technologies out there to facilitate our malignancies:
- API Metadata and documentation has a lot of momentum currently; API providers are putting strong efforts into providing API consumers with detailed technical descriptions of an API, including all we need for our attack - paths, parameters, message formats, etc. Several standards are at play:
- Swagger, RAML, API-Blueprint, I/O Docs, etc for REST APIs
- WSDL/XML-Schema for SOAP APIs
- JSON-LD, Siren, Hydra, etc for Hypermedia APIs
Have a look at the following Swagger definition for example:

As you can see, a helpful Swagger specification also tells us a lot about an API’s possible vulnerabilities, helping us target the attack.
- API Discovery: what if you have no metadata for the API you want to compromise? An alternative to getting an initial attack surface is to record interactions with the API using an existing client. For example, you might have an API consumed by a mobile app; set up a local recording proxy (there are several free options available) and direct your mobile phone to use this proxy when accessing the API – all calls will be recorded and give you an understanding of the APIs usage (paths, parameters, etc). There are even tools out there that can take recorded traffic and generate a metadata specification for you. As a hacker, it’s just as useful to you as it is to developers or honest testers.
- Brute Force: full disclosure: most developers aren’t famed for their creativity when deciding on API paths, arguments, etc. More often than not, you can guess at an API’s paths like /api, /api/v1, /apis.json, etc. – which might at least give you something to start with. And if the target API is a Hypermedia API, then you’re in luck; Hypermedia APIs strive to return possible links and parameters related to an API response with the response itself, which for a hacker means that it will nicely tell you about all its attack surfaces as you consume it.
So now you’re all set with core API technologies, security standards and your API’s Attack Surface. You know what API to strike and where to hit, but how do you make your attack?