

In this session, we're gonna look at two types of nodes that kubernetes operates on one is master and another one is slave and we're gonna see what is the difference between those and which role each one of them has inside of the cluster and we're going to go through the basic concepts of how kubernetes does what it does and how the cluster is self-managed and self-healing etc.
Worker Nodes:
- 3 Node Processes
- Container Runtime
- Kubelet
- Kube Proxy
- Each node has multiple pods on it
- 3 processes must be installed on every Node
- Worker Nodes do the actual work
- First process that needs to run on every node is the container runtime because application pods have containers running inside, a container runtime needs to be installed on every node.
- Process that actually schedules those and containers underneath is kubelet which is a process of kubernetes itself unlike container runtime that has interface with both container runtime and machine (worker node itself) because at the end of the day kubelet is responsible for taking that configuration and actually running apod or starting a pod with a container inside and then assigning resources from that node to the container like CPU, RAM and storage resources.
- Usually kubernetes cluster is made up of multiple nodes which also must have container runtime and kubelet services installed and you can have hundreds of worker nodes which will run run other pods and containers and repplicas of the existing pods like my-app and database as an example and the way communication between them works is using services which is sort of loadbalancer which basically catches the requests directed to the pod or application like database for example and then forward it to respective pod and third process that is responsible for forwarding the requests from services to pods is actually kube proxy.
- Kube proxy must be installed on every node and kube proxy has actually intelligent forwarding logic inside that makes sure that the communication also works in a performant way with low overhead for example if an application my-app replica is making a request database instead of service just randomly forwarding the request to any replica, it will actually forward it to the replicat that is running on the same node as the pod that initiated the reuqest thus this way avoiding the network calls overhead of sending the request to another machine.
- To summarise 3 node processes must be installed on every node in order for kubernetes cluster to function properly.

Master Nodes + Master Processes:
- We discussed above regarding worker nodes and processes in details but another question comes in mind so, how do you interact with this cluster?
- How to:
- schedule pod?
- monitor?
- re-schedule/re-start pod?
- join a new node?

- Answer to above ask is all these managing processes are done Master Nodes
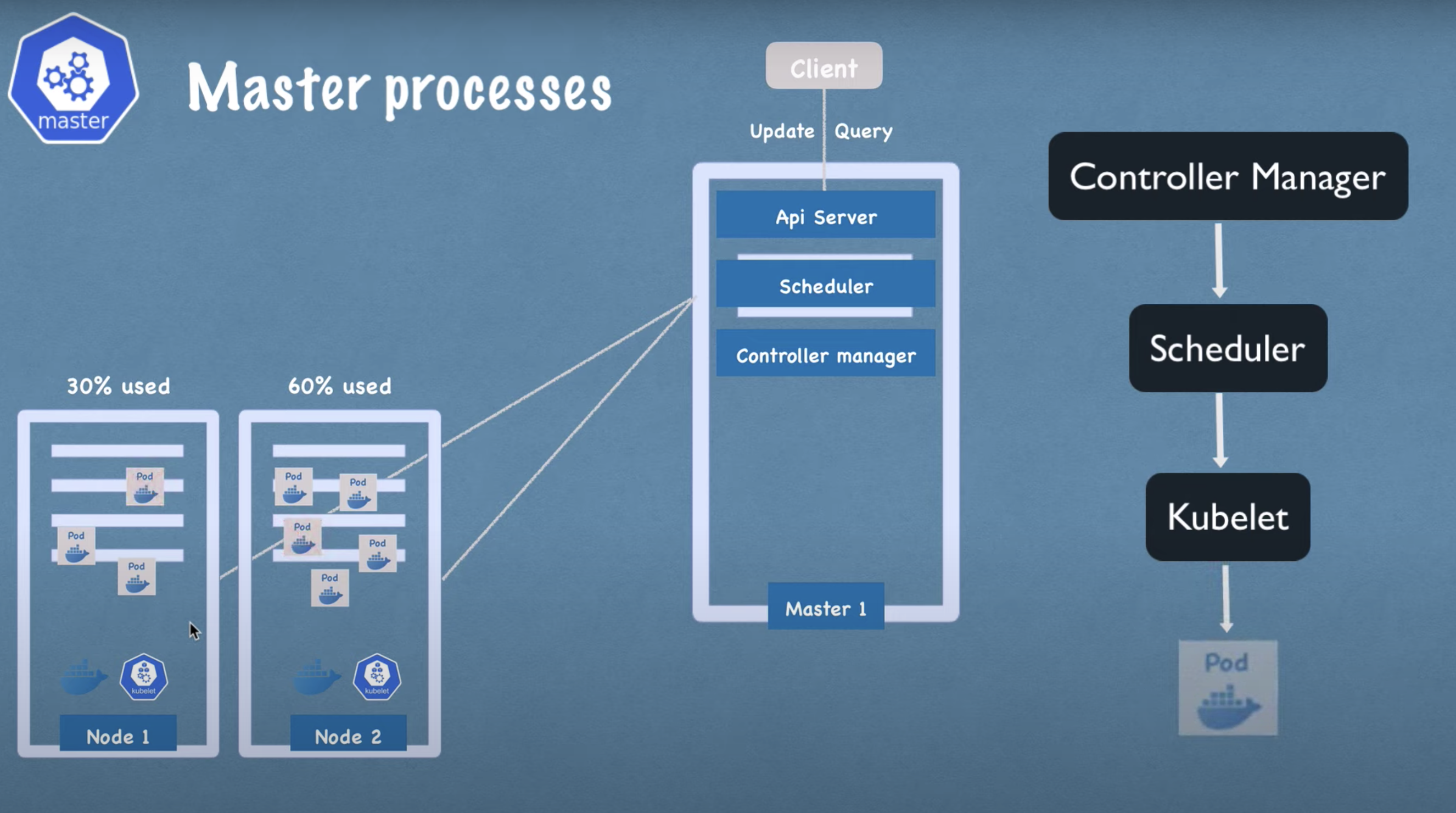
- There are 4 processes that run on every master node that control the cluster state and the worker nodes as well.
- API Server
- Scheduler
- Controller Manager
- etcd - the cluster brain
- API Server
- When you as a user want to deploy a new application in a kubernetes cluster, you interact with the APi Server using some client, it could be a UI like kubertest dashboard, could be commandline tool like kubelet etc. API server is like cluster gateway which gets the initial request which updates into the cluster or even the queries from the cluster and it also acts as a gatekeeper for authentication to make sure only authenticated and authorised requests get through to the cluster.
- That means whenever you want to schedule new pods, deploy new application, create new server or any other component, you have to talk to the API server on the master node and it validates your reuqtest and if everything fine then it forward your request to other processes.
- Also if you want to query the status os your deployment or the cluster health etc, you make a request to the API server and it gives you the response which is good for security because you have one entry point into the cluster.

- Scheduler
- As mentioned API server sends request to scheduler and scheduler has intelligent way to decide in which node pod has to put based on how much resources new pod needs and how much resources availables in the given nodes etc.

- Controller Manager
- Another crucial component because what happens when pods die on any node, there must be a way to detect that nodes died and then reschedule those pods asap.
- Controller manager detects cluster state changes like crashing of pods for example when pods die, controller manager detects that and try to recover the cluster state asap and for that it makes a request to the scheduler to reschedule those dead pods in the same cycle what we discussed during scheduler part discussion.
- etcd
- etcd is the cluster brain
- key-value store
- Cluster changes get stored in the key value store
- why we call it as cluster brain because all of those mechianism with scheduler and controller manager works because of this data, for example
- How scheduler knows what resources are available on each worker node.
- How does controller manager know that a cluster state changed in some way for example pods died or that kubelet restarted new pods upon the request of a scheduler.
- or when you make a query request to API server about the cluster health or for example you application deployment state where as API server get all this information from so all of this information is stored in etcd cluster.
- Actual application data is not stored in this one, only cluster state data.

Happy Learning !! :)

No comments:
Post a Comment