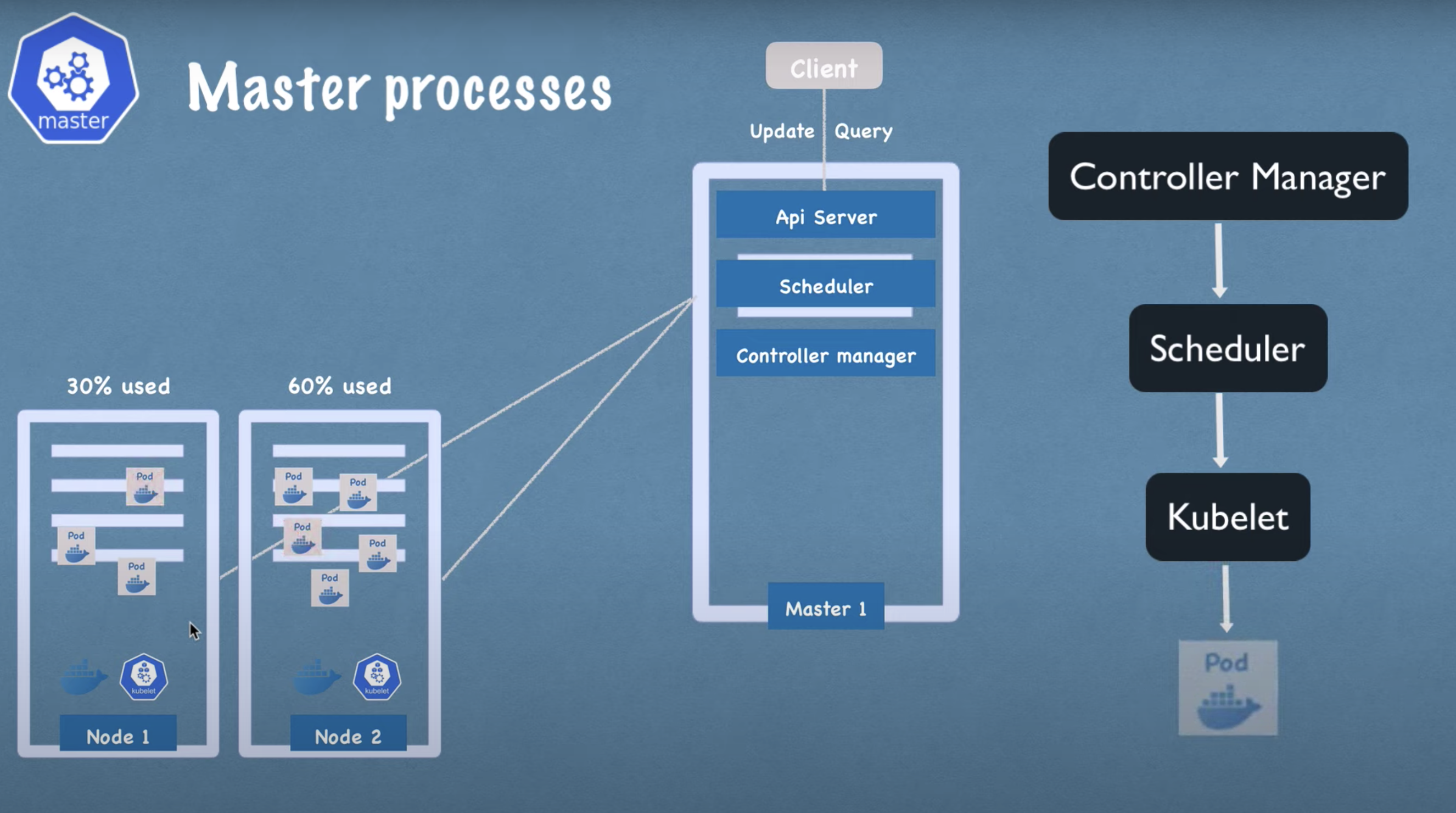
Whether you’re debugging a pod or scaling deployments, having the right commands at your fingertips can save hours of troubleshooting.
Here’s your quick-reference guide to essential kubectl commands used by DevOps, SREs, and Cloud Engineers every single day:
In below examples, assume "services" is the namespace given for your micro-services
🔹 Context & Cluster Navigation
kubectl config get-contexts – List all available contexts
kubectx <env-name> – Switch between environments
🔹 Nodes & Namespaces
kubectl get nodes – View all cluster nodes
kubectl get namespaces – List all namespaces
🔹 Pods & Deployments
kubectl -n services get pod <pod-name> – Get specific pod details
kubectl -n services get pods – List all pods in a namespace
kubectl -n services delete pod <pod-name> – Delete a specific pod
kubectl -n services get pods -o wide | grep ½ – Filter for unhealthy pods
🔹 Detailed Views
-o wide – Add node-level details
-o yaml – See full YAML output
kubectl describe pod <pod-name> -n services – Inspect pod specs
🔹 Inside the Pod
kubectl exec -it <pod-name> -n services -- /bin/bash – SSH into a pod
kubectl logs <pod-name> -c install -f -n services – View Init container logs
🔹 Scaling & Rollouts
kubectl scale deploy <pod-name> --replicas=3 -n services – Manual scaling
kubectl rollout restart deployment <pod-name> -n services – Restart a service
🔹 HPA & Canary Checks
kubectl get hpa <pod-name> -n services – Horizontal Pod Autoscaler status
kubectl describe canary <pod-name> -n services – Inspect a canary deployment
kubectl get canary -n services – List all canary-enabled pods
🔹 Logs & Troubleshooting (with Stern)
stern -n services <pod-name> -c <app-name> -t --since 1m – Tail recent logs
stern -n services geolayers-api-primary -c geolayers-api -t --since 1m | grep '<text>' – Filter logs with grep
🔹 Consul & Vault Checks
kubectl get pods -n configuration – View Consul/Vault status
stern -n configuration <name> – Stream logs from Vault
📘 Bonus: Official kubectl Cheat Sheet
💬 Which of these commands saved you recently — or is there a favorite one missing from the list?
Drop it in the comments and let’s build the ultimate K8s cheat sheet together. 👇
#Kubernetes #DevOps #CloudEngineering #SRE #kubectl #CheatSheet #K8sTips #PlatformEngineering #LinkedInLearning #Productivity